
新闻资讯
当前位置: 帮助中心新闻资讯辣椒HTTP&python爬虫实战!从入门到不放弃!

 假装很辣
假装很辣
网络爬虫是一个自动提取网页的程序,从互联网上采集网页并提取信息。
数据抓取是数据分析的前摇,它更多是指从结构或者非结构化的数据中提取到游泳信息的步骤。
1、确定目标网站:分析需要抓取的网页的具体的页面和网站的结构。
2、分析网页的结构:使用开发者工具查看网页的结构,并确定需要抓取的数据所在的位置。
3、编写爬虫代码:使用python的request数据库进行网页请求,使用BeautifulSoup或者XML对HTML文件解析。
4、存储数据:将抓取的数据存储到数据库中,例如MYSQL、MongoDB或者CSV文件。
5、在抓取过程中要注意遵守目标网站的robots.txt文件的规定,合规合法地进行数据抓取。
下面以抓取某电商网站(假设为一个结构类似京东/亚马逊的示例页面)的商品名称与价格为例。
⚠️ 本示例仅供学习和研究使用。
在真实抓取前,请务必查看目标网站的 robots.txt 文件,确保允许抓取。
import requests
from bs4 import BeautifulSoup
from urllib.robotparser import RobotFileParser
from urllib.parse import urljoin
import csv
import time
# ============= 1️⃣ 设置目标网站 ==================
base_url = "https://example.com" # 替换为你要抓取的站点
target_url = "https://example.com/search?q=手机"
# ============= 2️⃣ 检查 robots.txt 文件 ==================
robots_url = urljoin(base_url, "/robots.txt")
rp = RobotFileParser()
rp.set_url(robots_url)
try:
rp.read()
except Exception as e:
print("⚠️ 无法访问 robots.txt 文件,默认不抓取。")
exit()
# 检查是否允许抓取目标URL
user_agent = "MyCrawler" # 你的爬虫名称
if not rp.can_fetch(user_agent, target_url):
print(f"🚫 该网站的 robots.txt 禁止爬虫访问:{target_url}")
exit()
else:
print(f"✅ 已通过 robots.txt 检查,允许抓取:{target_url}")
# ============= 3️⃣ 抓取页面内容 ==================
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/117.0 Safari/537.36"
}
response = requests.get(target_url, headers=headers, timeout=10)
response.encoding = response.apparent_encoding
html = response.text
# ============= 4️⃣ 解析网页结构 ==================
soup = BeautifulSoup(html, "html.parser")
items = soup.find_all("div", class_="product-item")
data_list = []
for item in items:
name = item.find("span", class_="product-name")
price = item.find("span", class_="product-price")
if name and price:
data_list.append({
"name": name.text.strip(),
"price": price.text.strip()
})
# ============= 5️⃣ 存储抓取结果 ==================
with open("products_robot_safe.csv", "w", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=["name", "price"])
writer.writeheader()
writer.writerows(data_list)
print(f"✅ 共抓取到 {len(data_list)} 条商品数据,并保存至 products_robot_safe.csv")
# ============= 6️⃣ 延迟防爬间隔 ==================
time.sleep(2)
| 最佳实践 | 说明 |
✅ 使用 urllib.robotparser 检查 robots 文件 | Python 标准库自带,无需额外安装 |
✅ 为爬虫指定明确 User-Agent | 便于网站识别、允许你访问的路径 |
✅ 若 robots.txt 无法访问,则默认不抓取 | 防止误抓敏感页面 |
✅ 增加访问延迟(time.sleep()) | 模拟人类浏览行为 |
| ✅ 可添加日志记录 | 记录哪些 URL 被允许、哪些被拒绝 |
在进行网络数据采集的过程中,定期切换代理 IP 是保持采集稳定性和数据完整性的重要手段。不同 IP 的轮换不仅仅是为了分散访问压力,更是提升成功率与安全性的关键。
首先,切换 IP 可以有效避免被目标网站限制。当同一个地址在短时间内发出大量请求时,系统容易判断为非正常访问,从而触发限制或阻断。通过定期更换代理 IP,可以让请求分布更自然,减少被识别或屏蔽的风险。
其次,多 IP 轮换能显著提升抓取的成功率。网络访问中常见的错误状态码,如 403 Forbidden 或 429 Too Many Requests,往往与访问频率过高有关。使用不同 IP 发送请求,能让任务更加平稳地进行,避免重复失败或中断。
此外,切换代理还可以帮助模拟不同地区的访问效果。由于许多网站会根据访问者的地理位置展示不同的内容或价格,通过使用来自不同国家或地区的代理,可以更全面地了解网站在各区域的表现。
在某些平台中,不同的访问节点可能会显示略有差异的数据。通过轮换 IP,采集者能够获取更丰富、更完整的信息,从而在分析时获得更具代表性的结果。
1、完成账号的登录注册
2、完成实名认证
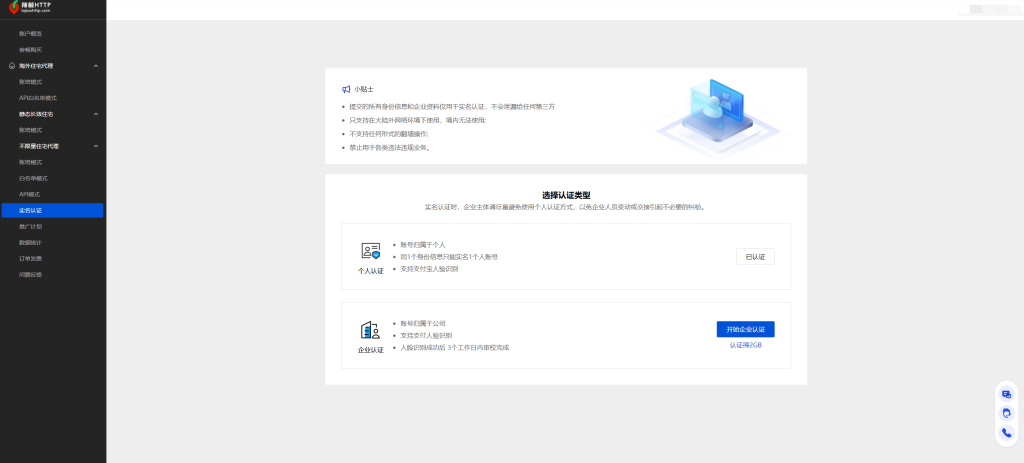
3、购买海外住宅代理,海外住宅代理这个是动态住宅代理,能够支持设定轮换和粘性。粘性模式下可以设定1-120分钟内不切换IP。轮换模式下,则支持用户每次请求都切换一次IP。这种海外住宅代理有效期能够保持90天。性价比特别高。
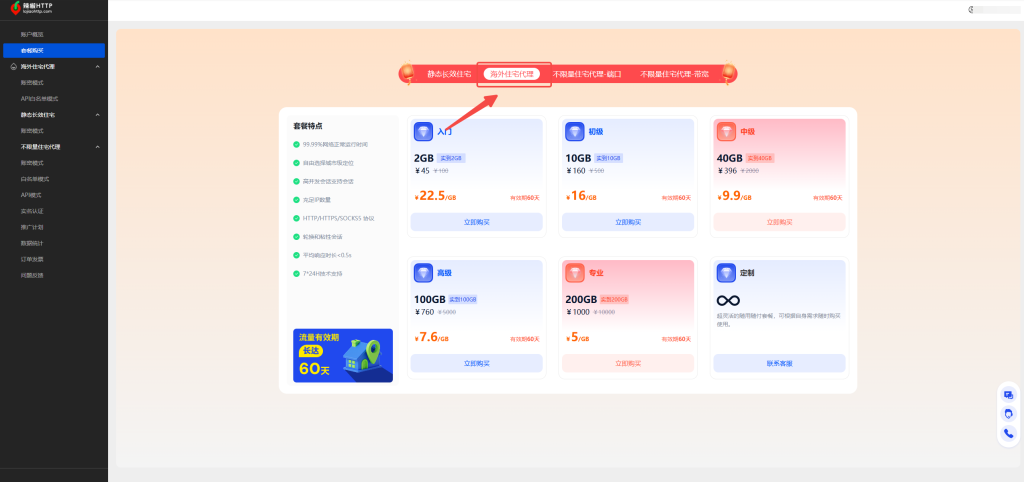
4、设定好需要提取的信息和轮换模式,点击生成按钮,即可获取代理。
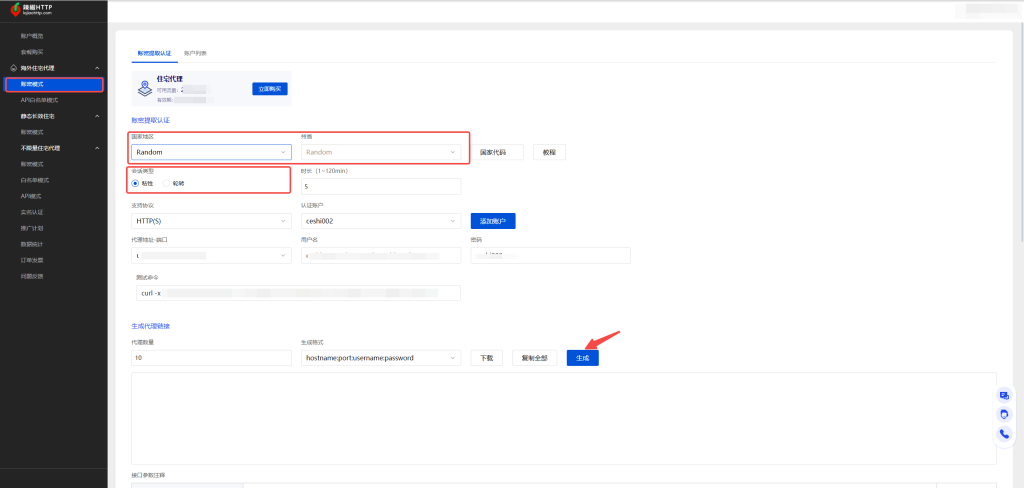
5、将代理结合在数据抓取中
import requests
# 代理信息(从辣椒HTTP后台复制)
proxy_host = "proxy.lajiaohttp.com"
proxy_port = "8000"
proxy_user = "user123"
proxy_pass = "pass456"
# 组合成完整代理地址
proxy_url = f"http://{proxy_user}:{proxy_pass}@{proxy_host}:{proxy_port}"
# 代理配置
proxies = {
"http": proxy_url,
"https": proxy_url
}
# 目标网站
url = "https://httpbin.org/ip"
# 发起请求
response = requests.get(url, proxies=proxies, timeout=8)
# 输出结果
print("返回内容:", response.json())
本文系统介绍了网络爬虫与数据抓取的核心概念与实现步骤,并重点强调了在执行过程中合规性与安全性的重要性。通过学习网页结构分析、编写抓取代码、解析HTML内容与存储数据,用户可以掌握完整的采集流程。同时,文中展示了如何结合 robots.txt 文件 检查、延迟访问与日志记录等最佳实践,确保数据采集过程符合网站规定。
此外,文章还深入说明了在数据抓取中使用 辣椒HTTP代理 的优势。通过轮换不同的住宅IP,爬虫可有效避免访问频率过高导致的封禁,提升抓取成功率,并实现多地区模拟访问,从而采集到更全面、真实的数据结果。辣椒HTTP支持动态与粘性模式,灵活适用于不同的数据采集需求,帮助用户在保证稳定与隐私的前提下高效完成采集任务。
当前辣椒HTTP正在优惠活动中,通过邀请码:666666 (6个6)注册可以获取限时优惠1.5GB的海外住宅代理,过时不候,仅支持前100名用户享有额外赠送。